
Since I’ve had little time to write code the last few weeks, let’s take a look at some past projects: today, we’ll take a look at Cubeland, my take on the cube voxel world game genre, à la Minecraft.
This isn’t actually even the first time I’ve tried doing this: the first attempt I made back in 2015 when I was still in high school. I gave it another crack my freshman year at university and made some advances, but performance was very poor. Having been inspired by a special topics computer graphics course, and perhaps more GPU power than is really necessary, I spent most of the winter holidays (and then some…) working on Cubeland.
After all, how difficult could it be to draw a bunch of cubes? Especially when writing code in a language like C++ that’s so much more efficient than Minecraft’s Java?
Turns out, very.
Engine
Instead of using an off the shelf game engine like Unity, I decided from the start I would write my own engine for this game. After all, the low level graphics stuff is the most fun! I’m using SDL2 to handle all my windowing needs and to get the GL context set up. This is SO much better than glfw or any of those other libraries used by tutorials out there. Infinitely more flexible, and it gives you a proper event loop which is absolutely crucial to handle input properly.
I also wrote some small object-oriented wrappers around OpenGL objects like textures, shaders, buffers, and so on. This makes working with them a little easier (much fewer raw GL calls scattered around) and allows for more effective error handling.
Beyond that, the engine uses a pretty bog standard deferred shading setup. In the first rendering stage, the world geometry is drawn into the G-buffer: a set of textures defining a particular on-screen pixel’s depth and material attributes such as color and surface normals. Later stages take this G-buffer as an input, and perform calculations like lighting, bloom, shadows, and even faking antialiasing using FXAA.
Cube Optimizations
At this point, with only a few days of work, I was able to get my first cubes on the screen. Success!
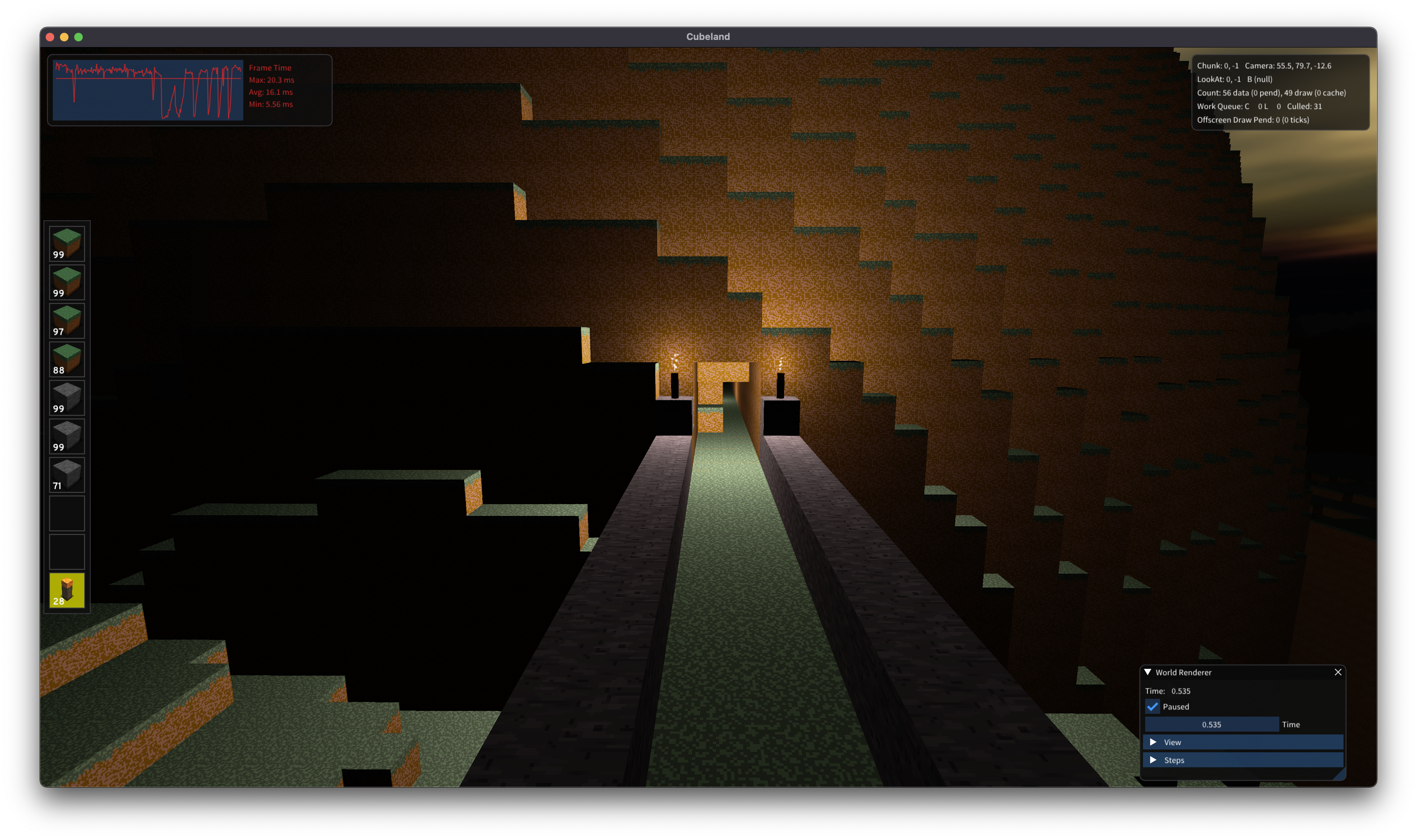
However, once I scaled this up to more realistic world sizes, the performance problem quickly became apparent. A large majority of the blocks aren’t visible whatsoever, yet we’re wasting both memory to store their vertices, and valuable draw calls to draw them. Since the geometry wasn’t ordered, we couldn’t rely on the GPU to do an efficient job of culling occluded fragments: some profiling revealed ridiculous 50-100x overdraw in some cases.
Each chunk (of 256x256x256 blocks) was further subdivided into globules, each of which are 1/4th the size on each axis. Each globule maintains its own buffers for drawing, using optimized (8 or 16 bit packed integers) representations for each block. When drawing a chunk, we simply request to draw all its constituient globules.
For each globule, we create a bitmap of which blocks are considered to be solid (such as dirt) and which are transparent (air or glass.) Using that map, it is trivial to detect whether a block may be visible: if any of the six adjacent blocks touching it are transparent, we decide to further check which faces are visible, and produce vertices for only those.
The downside of this approach, as implemented, is that there is a good bit of latency to turn chunk data in memory into vertices, since a lot of computation needs to happen. However, this all parallelizes excellently (each globule can be calculated individually once the air bitmap has been produced) so this is easily hidden. The absolutely huge benefit is that when updating a chunk (placing/removing blocks) updates are essentially instant.
While air blocks obviously aren’t drawn, glass blocks are: these are drawn in a second render pass after all solid blocks are drawn. The vertices (or rather, the index buffer) is sorted in descending distance from the camera. It is possible to implement order-independent transparency but I didn’t feel like going down that rabbit hole. There are not really enough transparent blocks to make this a huge performance problem.
A lot of great ideas for optimizations came from other folks who have done a similar project in the past; particularly, I found Dave’s Wiki incredibly useful. There were a few StackOverflow answers that provided useful insight as well.
User Interface
From the start, I wanted to be sure the engine had some sort of GUI system that I could use to build both debug tools (think little inspectors,) but was also versatile enough to serve as the base for the in-game interface. Thanksfully, the Dear ImGui library has basically every UI component you could think of, and is incredibly easy to integrate.
All UI is done in immediate mode, meaning every frame you issue the same UI calls. These build up the in-memory representation of the interface, which is then rendered after all the game content and simply alpha blended on top.
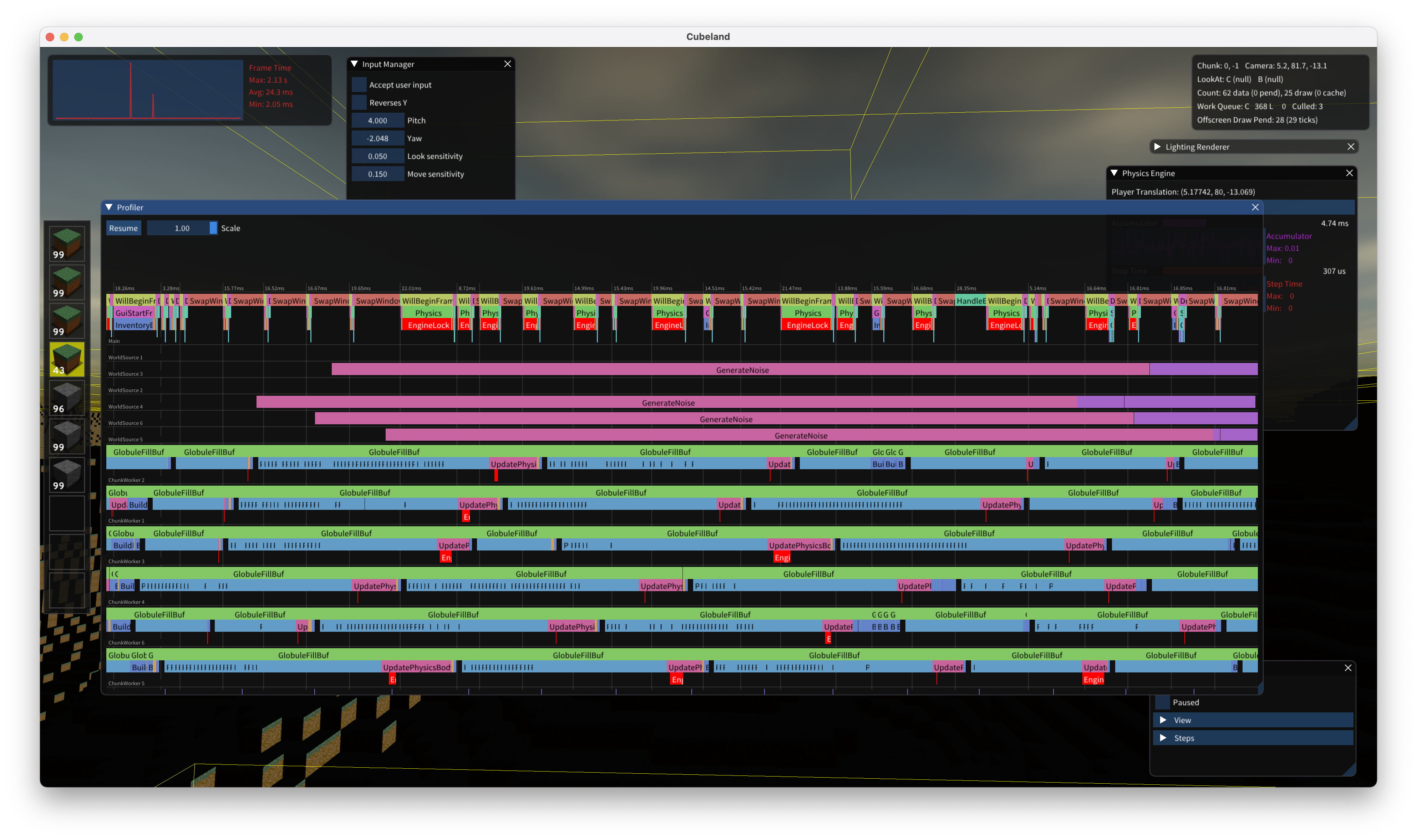
The flexibility of ImGui was quite surprising: all of the above debug views were created using it, including the built-in profiler that was incredibly useful in optimizing the app. The GUI is rendered in two passes; first the debug views, using the default smaller style, followed by the in-game user interface, which uses larger font sizes and spacings.
Fonts are standard TrueType fonts in TTF format, and are loaded from the resource bundle. All characters are then shoved into a font atlas, which is stored as a texture and used to render text.
Persistence
This was actually the first thing I implemented: before I even wrote a single line of graphics code. World files are nothing more than SQLite databases. While we don’t really need any of the features a database engine provides, it means the file format was much easier to work with outside of the game. It also is a proven, well-performing way to store data.
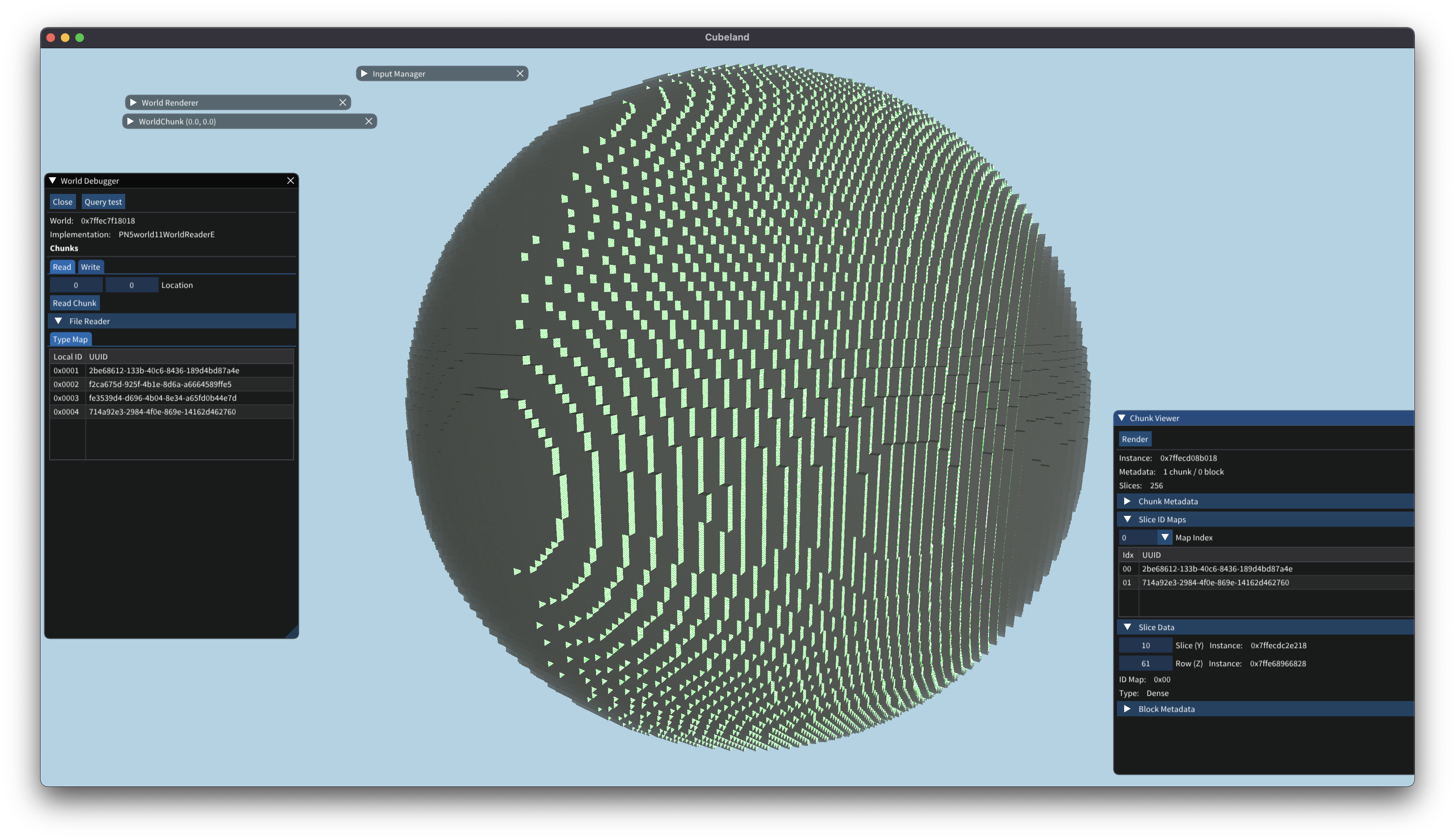
Picking a way to (de)serialize data was only half the battle. I also had to get the world data into the SQLite database somehow. Each chunk is “sliced” horizontally, to produce for each Y level, a 256x256 array containing an identifier for the block at that position. 1 Any additional per-block metadata (such as whether a dirt block has grown grass) are stored in a separate table, and reference the block by its full \((X,Y,Z)\) coordinate. Slice arrays are compressed and stored as a BLOB column in the database.
Memory Representation
A simple observation of most voxel worlds is that there is often a significant amount of empty space, filled with air – in other words, most chunks are rather sparse. So, simply storing chunks as a large 3-dimensional array, while fast, is very inefficient as far as memory goes.
Instead, each chunk is split into a slice, which represents a 256x256 set of blocks at a given Y value. These slices are then further subdivided into rows, which can be indexed either by the X or Z coordinate: this decision is made when the slice is deserialized, based on which representation uses the least memory.
Each row then actually stores the blocks that are contained in the slice. As with the on-disk storage format, block IDs are replaced by unique 8-bit integer values which index into a particular map. Each row can select one of 256 maps, and all maps are shared by all rows in a particular chunk. Accessor methods perform the translation to UUIDs as needed.
The engine can select one of two representations for a row. First is a traditional dense array; for dense blocks, the overhead is only the class’ vtable pointer and map ID. If a row is mostly air, it instead is allocated as a sparse row: this allocates the same amount of memory as a dense array row, but instead stores an ordered set of \((coord, id)\) tuples. This allows access in \(O(\log n)\) time; compared to just a simple linear search, the performance difference from doing a binary search is negligible (only a few processor cycles as the entire table is in cache) but does have a significant impact in large worlds.
Allocation
Even with moderately big worlds and render distances, assuming a “density” (the proportion of blocks vs air) of roughly 40%, a single chunk would need around 26k rows. Turns out, however, that basically every system’s general-purpose heap absolutely sucks for lots of small disjoint allocations: not just in terms of performance, but also in terms of memory overhead!
A simple solution here was to build my own allocator on top of the system allocator. These are very simple slab allocators that request from the system a relatively large chunk of memory, which is then handed out to satisfy allocations for different row types. Each chunk has its own allocator, which means that when a chunk is no longer needed, the allocators can simply release all of their memory.
For this same reason, these allocators currently do not really implement freeing rows; it would make allocation slower (due to the need to search for more than just one slab’s free list) and require some extra bookkeeping. Adding this would be reasonably trivial, but gains very little benefit: it may save a few K of RAM when updating blocks, but the second a block is unloaded and loaded again, this becomes a non-issue.
Multiplayer
Implementing multiplayer on top of the existing chunk persistence model was actually rather simple. Instead of reading slices from an SQLite store, they’re received from a server over the network. Other than that, the exact same codepaths deserialize it and read it.
Additionally, a few extra network packets indicate individual block updates made by other clients, which are applied to the in-memory chunks as needed.
However, overall multiplayer support is very much experimental. There is a very basic text chat, but no way to see other players yet. I implemented it over the course of a weekend just to prove a point (go figure…) but it should be reasonably easily extensible. A web API handles authentication, but this is all easily stubbed out for development.
Conclusion
As with most of my projects, the source code is available on GitHub. This includes some bespoke tools and all resources otherwise required for the game to work. There’s quite a few dependencies, and hasn’t been tested to compile (or even run) on anything other than macOS Big Sur and FreeBSD 13.
There are definitely a lot of subtle bugs in the rendering component of the engine, and in general it could probably use a bit of optimization. Performance is, of course, excellent on my Mac Pro, and quite satisfactory on my 2015 iMac that I use for testing. It also apparently does work on the new Apple Silicon M1-based hardware (after doing a lot of cursing because some dependencies can’t be built as fat binaries) but it’s running on borrowed time using OpenGL anyhow.
Everything in that repo is made available under the 2 clause BSD license, as with essentially all of my other projects. (At the time of writing, I hadn’t updated the repo to reflect this… maybe by the time y’all read this it will be.)
For now, I don’t have any plans to continue working on the project actively. I may write some later posts about it to detail some of the techniques I’ve implemented; if there is anything that you, my dear reader, would like to read about, please let me know.
Blocks are identified by an UUID in the game. However, the overhead of storing a 16-byte value for each block quickly becomes unsustainable; instead, in many places, a layer of indirection is applied where a small integer (usually 8 or 16 bits, depending on the use case) is used as an index into an UUID table. ↩