Thanks to the recent snowcopalypse here in Texas, I had a bit over a week with nothing but an old ThinkPad loaded with Intel reference manuals. So I did what any reasonable person would do.
Start writing yet another operating system, of course.
Thankfully, it turns out with a little over a week of time, and with a lot more knowledge than the last time I tried doing this, I actually have ended up with some surprisingly workable results. I’ll describe a little bit of the design motivation, and where I’m at below.
Kernel
Something about the design of microkernels has always really appealed to me, so that’s what I tried to emulate in the design of this system. The kernel offers only a few simple services: physical and virtual memory management, thread scheduling and context switching, interrupt routing, and supporting timers. I’ve drawn a lot of inspiration from the Windows NT kernel, as well as microkernels such as L41 and Mach.
Internally, the kernel is divided into three components:
Architecture
This is where stuff specific to the CPU architecture is implemented: in our case, this consists of interfaces to do context switching (which requires architecture-specific knowledge of stack frames, especially for getting from kernel to user mode) and gathering some system information (support for the NX bit, page size) and exception handling.
Architecture code is also responsible for manipulating the underlying virtual memory tables that the processor reads; it exports a C++ class that’s embedded in all kernel maps that actually handles those operations, while the kernel only concerns itself with the higher level abstraction of a VM map entry, rather than individual pages: this makes it trivial to make use of features such as large pages transparently.
In the case of the x86 architecture, this is also where support for all the lovely exciting data structures2 goes. Most of this ties in with context switching and isn’t exported as an interface to other kernel components, so this works out pretty well.
It’s of note that on x86, we support the NX bit. This isn’t implemented on anything before Pentium 4 (or thereabouts) so support for it is detected at runtime via CPUID. This however requires we use PAE, which extends all paging entries from 32-bit to 64-bit. This allows us to access more physical memory, and also gives us a convenient set of extra flags, one of which is NX. These larger structures mean we can’t use the recursive mapping3 as we’re used to: we’d lose out on a
whole gig of VM space!
The problem is that PAE adds a third level of lookup indirection in the form of the Page Directory Pointer Table, which consists of four entries, each mapping a gig of VM space. I cheat and get around this by mapping the PDPT as a page directory: however, this requires extra cleanup before we load the PDPT again later: its format is different than that of page table entries. Specifically, the accessed/dirty bits are reserved in the PDPT. If they’re set – as they will be by the MMU – the
processor will take a fault when CR3 is loaded with a new PDPT address. That extra cleanup masks off a few bits if the page directory was changed when it’s activated on the next context switch. It’s a little annoying and feels a little hacky, but meh.
Platform
Platform code contains a decent bit more functionality than the architecture: the idea being that the platform defines all the interfaces for dealing with things like interrupts, timers, and debug output. This enables, at least in theory, for platforms to be able to support multiple CPU architectures.
Startup code (written in assembler) that gains control from the bootloader is implemented here. It’s responsible for getting the system into a somewhat sane state, and setting up initial paging before jumping to the kernel entry point.
On x86, we identity-page the first 1G of VM space, then relocate the kernel to above the 3G boundary, before jumping into the kernel code. Along the way, it parses bootloader information4 and actually parses some ACPI structures to find and configure interrupt controllers. For convenience, I completely disable the legacy 8259 PICs and use only the New and Improved(tm) APIC. Accessing them is a lot quicker since it’s MMIO as compared to IO ports. This also gives us the IOAPIC, a much nicer way of dealing with external interrupts than the PIC.
Timers are also implemented in the platform code. These are used by other parts of the kernel to implement things like timed blocks and periodic cleanup work. Additionally, the timer tick drives the scheduler’s preemption. Most platforms have more than one time source5 so the platform code is responsible for selecting the best one depending on the current situation. For example, a future optimization may be to use low resolution (and thus, lower power) clocks when possible.
Generic
This is by far the largest part of the kernel codebase. It implements all of the system calls, as well as logic for all other parts of the system. It can further be subdivided into several subcomponents:
Physical Memory
Provides an interface to allocating entire pages of physical memory. A bitmap is kept that indicates which pages are free and which are allocated. This means it’s pretty easy to leak physical pages, but that’s why this API is not used directly by the rest of the kernel.
Virtual Memory
Essentially all meemory mappings after the kernel has booted up fully go through the VM layer. This is centered around maps – of which each task has one – a representation of a virtual address space. Each such map contains multiple map entries, which define a particular contiguous region of virtual memory.
Regions can be backed by anonymous memory, which is acquired on demand from the physical pool; or by raw physical addresses, for things like MMIO. Each memory region can have different protection and cacheability levels, and they can indeed be shared between multiple maps at different base addresses.
Scheduling
Defines the task and thread structures. Tasks are really just thin containers around one or more threads, and a virtual memory map. Additionally, on some architectures, tasks may have additional state associated with them: on x86, this is its IO permission bitmap, if it’s requested any access to IO ports.
Currently, I have a really, REALLY shitty basic round-robin priority scheduler implemented. It keeps a ready queue for each of the 5 priority levels I have defined. It handles preempting running threads (using the timer interrupt) at arbitrary quantums (defined per priority level) and does minor priority adjustments to ensure lower priority threads aren’t starved of processing time.
Threads are where all the blocking is implemented. At the moment, a thread can only block on a single object, but there’s no reason why this couldn’t be expanded to multiple objects. This will be required to implement a WaitForMultipleObjects()-like call.
IPC
Most important in a microkernel is of course a robust interprocess communications infrastructure. The kernel has two different IPC mechanisms:
- Message passing over unidirectional ports: Messages are buffered in a (bounded) queue in the kernel, meaning that they’re always copied out of the sending task. Similarly, messages are always copied out of this queue into the receiving task’s memory. This makes it rather inefficient for larger messages, but the overhead of copying a few hundred bytes is not too bad. Eventually, I’d like to add an optimized case for small messages that can be passed entirely in registers.6
- Notification bits: Primarily intended for use in interrupt handlers, notifications offer an asynchronous mechanism to indicate that some sort of event took place and needs attention. All threads have a notification word, on which they may block. Other events in the system may set bits in a thread’s notification word: if the logical AND of the word, and the mask provided by the blocking thread is nonzero, it will be unblocked.
There’s also shared memory: there’s no special support for this in the kernel: it’s enough to simply get the handle to a virtual memory region and map it into another task’s address space.
Syscalls
With some cooperation from the architecture code (which implements the actual syscall entry trampoline7) all the syscalls are handled in the kernel. This really just boils down to a big array of function pointers into which the function number is an index. There’s provisions for optimizing some system calls (such as message sends or notifications) but none of that has been done yet.
Most syscalls are just thin wrappers around operations on kernel objects. These objects – tasks, threads, virtual memory maps, and ports – are accessible to userspace through opaque handles. Handles encode an index into a table (which contains pointers to the actual objects,) a type value that indicates which table to look up, and an epoch value. Every time a slot in the array is re-used, its epoch is incremented by one: this way, we can detect when stale handles are used and warn appropriately.
There are no real permissions checks anywhere here yet: any task can do anything to any other task’s objects. I plan to eventually extend this with some sort of rights-based system that defines what tasks can perform what actions on what objects. This will also extend to gating off entire syscalls at once, in a manner similar to pledge(2) on OpenBSD.
Userland
There’s really not a whole lot here yet; we have enough to launch executables, do some dynamic linking, and read from a bundle loaded by the bootloader, but that’s it. There’s no drivers for anything yet, though the infrastructure for that is slowly getting there.
Runtimes
Right now, there’s what I like to call ShittyLibC which is my very crappy take on a C library. It implements most string/stdio/stdlib routines (most of which are shamelessly borrowed from OpenBSD and FreeBSD’s libc,) and implements the file IO on top of the native RPC-based API. Additionally, I wrote an implementation of the C11 threads API (very similar to pthreads) on top of the native system calls for thread creation. This has hooks for thread-local storage and other such fun stuff.
On top of that, we build libc++ out of the llvm toolchain we already have to provide the C++ runtime. This includes the ABI components and the unwind library. Having a full C++2x runtime to write code in is super, super nice.
Dynamic Linker
To make everything go, there’s a pretty mediocre dynamic linker. It’s enough to get things going, but has a few bugs: for example, vtables for classes defined in dynamic libraries simply don’t work. It does support thread-local storage and provides some runtime APIs as well.
There’s no support yet for sharing the read-only regions of shared libraries though. This will eventually get implemented with the assistance of a dynamic link server.
Drivers
While there’s no drivers implemented yet, I have started doing some preliminary support to enable writing them later. Drivers run as regular userspace tasks, so they can be lauched the same as any other task.
Hardware is enumerated via ACPI, thanks to the ACPICA reference implementation. This is used to parse the ACPI tables and execute AML to get things like PCI interrupt routings. This then is used to start PCI root bridge drivers, which then enumerate all devices connected to them and in turn load drivers for them.
The way this all works is pretty similar to how IOKit on Apple platforms; drivers specify various match criteria (such as name, PCI vendor/device ID, etc.) and the driver server will automatically start them as new devices are discovered. When drivers have completed initializing, they register themselves with the driver server.
Registered drivers are stored in a sort of tree-like structure in the driver server. This gives us a clear path of how a device is connected, especially when busses like USB where we can have complex topologies come into play.
To support userspace drivers, the kernel supports delivering interrupts to userspace threads via notification bits. On x86, a task can also request to add IO port ranges to its task-wide whitelist, so that it can directly read and write IO ports with the IN/OUT instructions.
Wrapping Up
Hopefully this has been a somewhat interesting read. I’ve always enjoyed reading posts of other OSDev folks (recently: SerenityOS) so I figured it was only apt to “revive” my blog with some content. I’ll try to keep posts going, likely mostly on userspace components since that’s where most of the work remains. A lot of the kernel will likely get refactored sooner or later though: being written while being basically frozen and without electricity led to some very… interesting design choices. (Nevertheless, I’m impressed the THREE separate batteries in my old T60 could still give me 12 hours of runtime. Seriously impressive.)
Currently, there’s really not much to show off – there’s not even a VGA console. All output goes through the platform spew port, which really just ends up being a serial port because it’s so stupid simple to interface with. Nevertheless, here’s it running in qemu, with some debug output showing active tasks and threads:
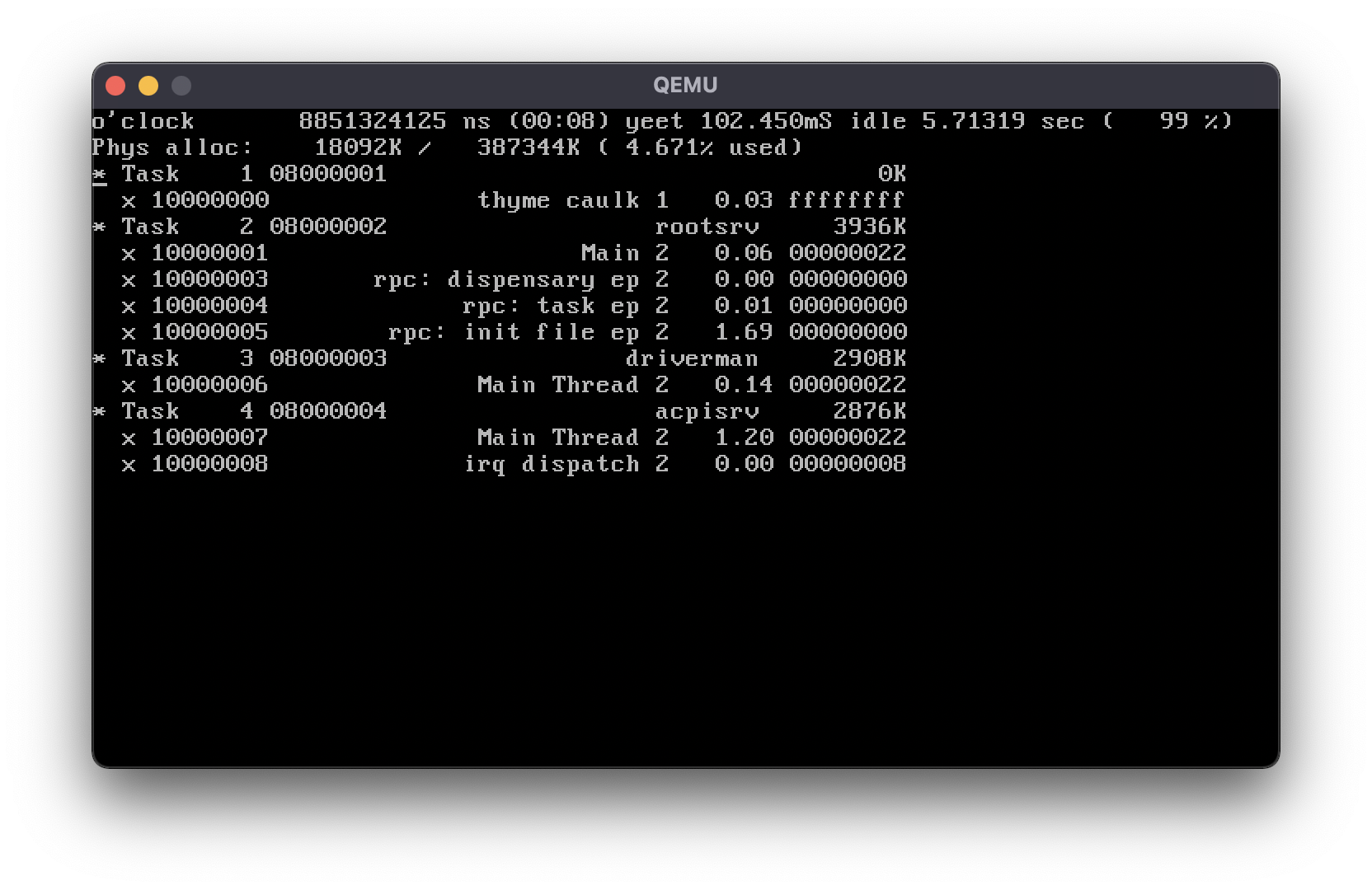
Eventually, I’d like to get this system fully self-hosting, with a graphical user interface. A network stack would be wonderful as well, which would let me port a whole bunch of neat software, including perhaps even web browsers. Having a native toolchain in LLVM really makes porting software a breeze.
Until then, the code for everything is on GitHub. Included is a script to boostrap a toolchain, which then works with the included CMake configurations to build the kernel and userspace components. Documentation in this area is definitely lacking, but honestly, at this point the only thing documented well in this system are the syscalls8.
L4 really is beautiful, and I don’t think I could ever write a microkernel that does it justice. I was definitely more inspired by its simplicity and performance than any of its implementations. ↩
For 32-bit Intel, to get a Protected Mode going, you’ll need at a minimum to set up the Global Descriptor Table that defines memory segments (which are basically unused, except for supporting thread-locals via the
%gsregister) and task gates; the Interrupt Descriptor Table which is required for CPU exceptions, external interrupts, and software interrupts. This is all in addition to page tables, which get complicated with PAE. ↩This technique relies on the orthogonality of x86 paging structures, e.g. the page directory and page tables themselves. The last page directory points to itself, allowing each of the 1024 4K pages in that region to map to the contents of a page table. This article by Thomas Lovén gives a good overview of how this works. ↩
Currently, we’re loaded by GRUB2, so we can make use of multiboot2. This is a minor improvement over the original multiboot protocol in that it allows us to get some more information. ↩
For example, on any reasonably modern x86 machine, there’s at least three different timers: the real-time clock, the legacy 8254 timer and the timer provided in the APIC. Most machines will also have a HPET which was meant as a replacement for both the RTC and PIT. Ironically enough, since it’s such a huge pain in the ass to determine the APIC timer frequency, I “eyeball” it against the legacy PIT on startup. This is very cursed but that’s the PC for ya. ↩
x86 has basically no registers: I’ve thought of using the XMM registers, typically used for SIMD math, for passing these messages without copying. This works in theory, and is the origin of why message buffers must be 16-byte aligned: this allows using the fast
MOVAPSinstruction to copy data. ↩Implementing the syscall trampoline in the architecture code is necessary because it’s very difficult to get the user -> kernel transition right AND fast. On x86, you need to use the SYSENTER/SYSEXIT instructions to get the best performance, which work in some rather strange ways the kernel really needn’t concern itself with. ↩
These are in a very neatly formatted $\LaTeX$ document here. ↩